A Inteligência Artificial está avançando a passos largos, mas o custo computacional e a demanda por memória dos Large Language Models (LLMs) são desafios persistentes. É nesse cenário que o Google entra em campo com uma solução promissora: o TurboQuant. Lançado recentemente, este conjunto de algoritmos e biblioteca visa otimizar radicalmente a eficiência de LLMs e motores de busca vetorial, componentes cruciais para sistemas RAG. Mas o que exatamente é o TurboQuant e como ele promete transformar a maneira como interagimos com a IA? Prepare-se para mergulhar na TurboQuant e Compressão KV para LLMs e entender por que esta é uma das novidades mais quentes do momento.
TurboQuant: A Nova Ferramenta do Google para Otimização de LLMs
O Google, gigante da tecnologia e inovação em IA, apresentou o TurboQuant como uma resposta direta à crescente necessidade de modelos de linguagem mais enxutos e eficientes. Trata-se de uma suíte algorítmica e uma biblioteca avançada, projetada especificamente para aplicar técnicas de quantização e compressão a dois pilares da IA moderna: os Large Language Models (LLMs) e os motores de busca vetorial. A relevância desses motores é amplificada pelo seu papel indispensável em sistemas de Recuperação Aumentada por Geração (RAG), que permitem que LLMs acessem e integrem informações externas para gerar respostas mais precisas e contextualizadas. O objetivo central do TurboQuant é reduzir o consumo de memória e a latência, tornando a IA generativa mais acessível e economicamente viável.
Entendendo a Compressão KV e a Quantização em Large Language Models
Para apreciar o impacto do TurboQuant, é fundamental compreender os conceitos de compressão KV e quantização. Ambos são métodos poderosos para otimizar o uso de recursos computacionais, especialmente em modelos de IA que lidam com grandes volumes de dados e cálculos complexos.
A Importância da Compressão KV para a Eficiência de LLMs
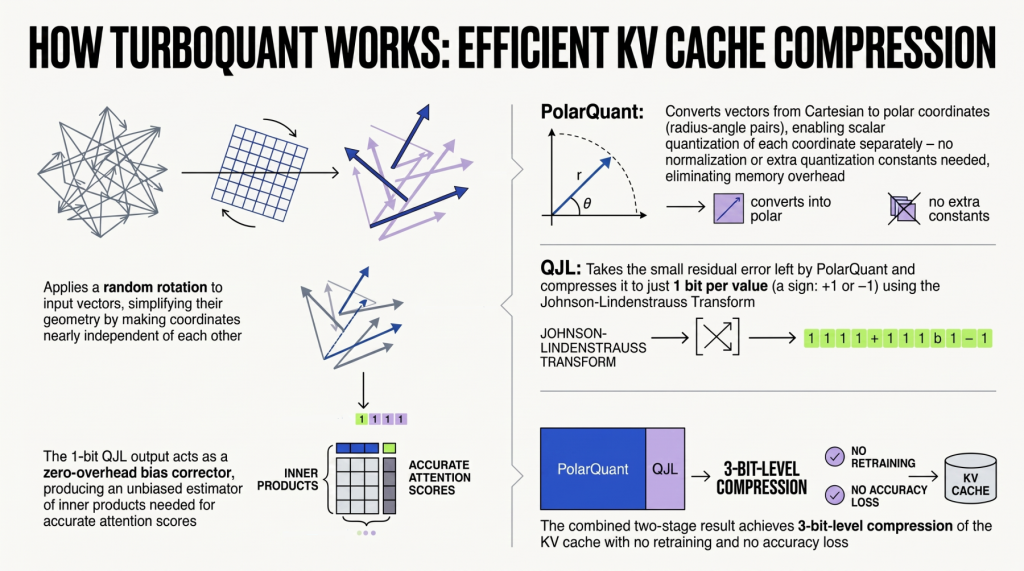
Um dos maiores gargalos de desempenho em LLMs, especialmente aqueles que processam sequências longas de texto, é o chamado KV Cache (Key-Value Cache). Durante o processo de inferência, o modelo gera e armazena chaves (Keys) e valores (Values) para cada token processado. Isso é crucial para que o modelo possa “lembrar” o contexto já gerado e gerar a próxima palavra de forma coerente. No entanto, à medida que a sequência de tokens aumenta, o KV Cache cresce exponencialmente, consumindo uma quantidade enorme de memória de vídeo (VRAM) e, consequentemente, impactando a velocidade e o custo da inferência. A compressão KV, como o nome sugere, busca reduzir o tamanho desse cache sem comprometer significativamente a qualidade das gerações do modelo. Ao aplicar algoritmos inteligentes, o TurboQuant comprime essas chaves e valores, liberando memória e permitindo que mais tokens sejam processados por vez ou que modelos maiores sejam executados em hardware menos potente.
Quantização: Menos Bits, Mais Velocidade
A quantização é outra técnica de otimização poderosa que o TurboQuant emprega. Em termos simples, ela consiste em reduzir a precisão numérica dos parâmetros de um modelo de IA. A maioria dos LLMs é treinada usando pesos e ativações representados por números de ponto flutuante de 32 bits (FP32). A quantização converte esses números para representações de menor precisão, como 16 bits (FP16), 8 bits (INT8) ou até 4 bits (INT4). Embora isso possa introduzir uma pequena perda de precisão, o ganho em termos de memória e velocidade de processamento é gigantesco. Modelos quantizados ocupam menos espaço em disco, carregam mais rápido e, o mais importante, executam a inferência com maior velocidade, pois CPUs e GPUs podem processar dados de menor precisão de forma mais eficiente. O TurboQuant combina essas técnicas para oferecer uma otimização robusta, visando manter a acurácia enquanto maximiza a eficiência.
TurboQuant em Ação: Otimizando Motores de Busca Vetorial e RAG
Além dos LLMs em si, o TurboQuant estende seus benefícios para os motores de busca vetorial, um componente essencial na arquitetura de muitos sistemas de IA modernos, especialmente os RAG. Sistemas RAG (Retrieval-Augmented Generation) revolucionaram a forma como LLMs acessam informações, permitindo que eles consultem uma base de conhecimento externa em tempo real para enriquecer suas respostas, evitando “alucinações” e fornecendo dados mais factuais. Para aprofundar-se em como o RAG funciona e suas aplicações, confira nosso artigo sobre [LINK_INTERNO].
O Papel Vital dos Motores de Busca Vetorial em Sistemas RAG
Em um sistema RAG, a consulta do usuário e o conteúdo da base de conhecimento são transformados em vetores (representações numéricas). O motor de busca vetorial então encontra os vetores mais “próximos” (semanticamente semelhantes) na base de conhecimento. É essa recuperação de informações relevantes que permite ao LLM gerar uma resposta mais informada. A eficiência desses motores de busca depende diretamente de quão rapidamente eles podem armazenar, indexar e comparar esses vetores. A aplicação das técnicas de compressão e quantização do TurboQuant a esses motores resulta em índices vetoriais menores e buscas mais rápidas, acelerando todo o pipeline do RAG. Isso significa que aplicações de IA baseadas em RAG, como chatbots de suporte ao cliente, assistentes de pesquisa e ferramentas de análise de dados, podem operar com maior agilidade e menor custo.
Por Que o TurboQuant é uma Notícia Importante para o Cenário da IA?
O lançamento do TurboQuant pelo Google transcende a esfera puramente técnica e tem implicações significativas para o futuro da Inteligência Artificial. Primeiro, ele democratiza o acesso a tecnologias de ponta. Ao tornar LLMs e sistemas RAG mais eficientes e menos famintos por recursos, empresas menores e desenvolvedores individuais podem experimentar e implantar soluções de IA generativa que antes estavam fora de seu alcance devido ao alto custo de hardware e computação. Segundo, ele impulsiona a inovação. Com menos preocupações sobre o gargalo de memória, pesquisadores e engenheiros podem focar na criação de modelos ainda mais complexos e capazes, sem sacrificar a viabilidade operacional. Terceiro, o TurboQuant reforça a tendência da indústria em direção a modelos mais sustentáveis e eficientes, um passo crucial para reduzir o impacto ambiental da computação de IA em larga escala. É uma solução que responde a uma dor real do mercado, prometendo não apenas otimização, mas uma mudança de paradigma na forma como pensamos sobre a implantação de LLMs.
O Que Esperar do Futuro da Otimização de Modelos de Linguagem?
A otimização de modelos de linguagem, incluindo a TurboQuant e Compressão KV para LLMs, é uma área de pesquisa e desenvolvimento em constante ebulição. Espera-se que vejamos ainda mais avanços em técnicas de quantização, poda (pruning) e destilação de modelos, buscando encontrar o equilíbrio perfeito entre desempenho, tamanho e eficiência. A competição entre empresas como Google, OpenAI, Meta e startups emergentes certamente acelerará a inovação. Além disso, a integração dessas otimizações diretamente nos frameworks de Machine Learning e nos chips de IA dedicados será cada vez mais comum, tornando a aplicação dessas técnicas ainda mais simples para os desenvolvedores. O futuro aponta para um cenário onde a IA de alto desempenho não será um privilégio de poucos, mas uma ferramenta amplamente disponível e escalável.
O TurboQuant do Google representa um marco importante na jornada da IA em direção à eficiência e sustentabilidade. Ao abordar os desafios cruciais da compressão KV e da quantização, ele não apenas otimiza o desempenho dos Large Language Models e dos sistemas RAG, mas também abre portas para uma adoção mais ampla e inovadora da inteligência artificial em diversas aplicações. Com menor custo e maior velocidade, a IA generativa está cada vez mais próxima de se tornar uma ferramenta onipresente e verdadeiramente transformadora. Acompanhe as últimas novidades do Google AI aqui.
FAQ: Perguntas Frequentes sobre TurboQuant e Compressão KV
O que é o TurboQuant?
O TurboQuant é uma nova suíte algorítmica e biblioteca lançada pelo Google para aplicar compressão avançada e quantização a Large Language Models (LLMs) e motores de busca vetorial, otimizando seu desempenho e reduzindo o consumo de memória.
Como a compressão KV impacta o desempenho dos LLMs?
A compressão KV (Key-Value) reduz o tamanho do KV Cache, que armazena o contexto gerado pelo LLM. Ao comprimir esse cache, o TurboQuant diminui o consumo de memória, permitindo maior velocidade de inferência e a execução de modelos maiores ou sequências mais longas em hardware com menos VRAM.
Qual a diferença entre compressão e quantização no contexto do TurboQuant?
A compressão, especificamente a compressão KV, visa reduzir o espaço ocupado pelo cache de contexto do LLM. A quantização, por outro lado, diminui a precisão numérica dos pesos e ativações do modelo (ex: de FP32 para INT8), o que também reduz o consumo de memória e acelera o processamento, ambos sendo técnicas complementares para otimização.
Qual o principal benefício do TurboQuant para sistemas RAG?
Para sistemas RAG (Retrieval-Augmented Generation), o TurboQuant otimiza os motores de busca vetorial. Isso significa que os índices vetoriais ficam menores e as buscas por informações relevantes são mais rápidas, resultando em respostas mais ágeis e eficientes dos LLMs.
Gostou da notícia?
Inscreva-se na nossa newsletter e receba as principais novidades sobre inteligência artificial diretamente no seu e-mail.





