A integração de Large Language Models (LLMs) em fluxos de trabalho de aprendizado de máquina tem sido um desafio para muitos desenvolvedores. No entanto, uma ferramenta promissora está mudando esse cenário: o Scikit-LLM para resumo de texto. Essa biblioteca inovadora promete simplificar a vida de cientistas de dados e engenheiros de IA, unindo a familiaridade do ecossistema Scikit-learn com o poder generativo dos LLMs.
Com a capacidade de resumir textos usando LLMs de forma intuitiva, o Scikit-LLM abre novas portas para aplicações em Processamento de Linguagem Natural (NLP), tornando tarefas complexas mais acessíveis e eficientes. Vamos mergulhar no que essa ferramenta representa para o futuro da IA e como ela pode otimizar seu trabalho.
<h2>O Que é o Scikit-LLM e Por Que Sua Abordagem Inovadora Importa?</h2>
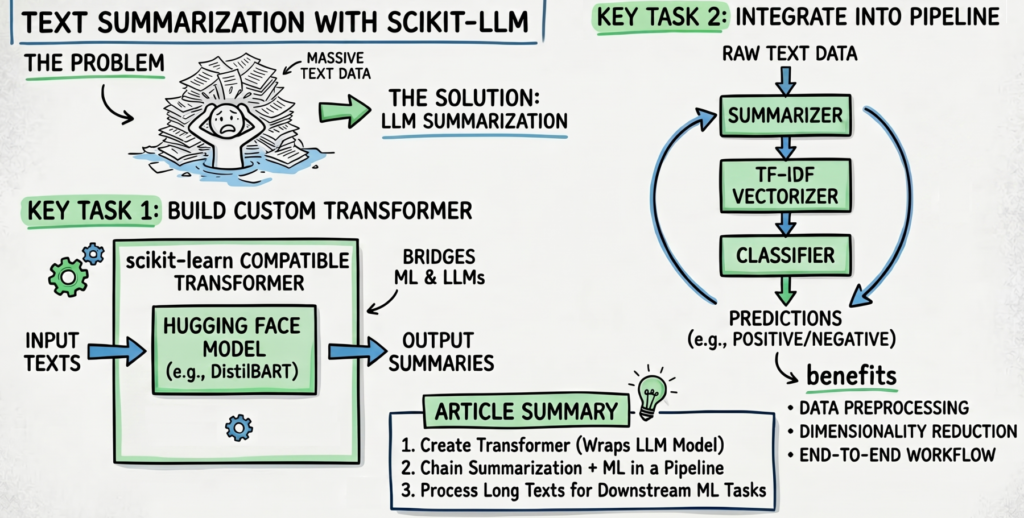
O Scikit-LLM é uma biblioteca de código aberto que estende o popular framework Scikit-learn, trazendo os poderosos Large Language Models (LLMs) para dentro desse ecossistema familiar. Criado por Sebastian Raschka, renomado autor e especialista em Machine Learning, o Scikit-LLM não é apenas mais uma API para LLMs; ele foi projetado para permitir que cientistas de dados usem LLMs como qualquer outro estimador do Scikit-learn, com métodos como .fit() e .predict().
A inovação reside na sua capacidade de abstrair a complexidade da prompt engineering e da interação direta com APIs de LLMs, oferecendo uma interface limpa e consistente. Isso é crucial porque democratiza o acesso às capacidades avançadas dos LLMs, tornando-os ferramentas acessíveis para uma gama maior de projetos e profissionais já familiarizados com o Scikit-learn. Em vez de reescrever lógica complexa para cada tarefa, o Scikit-LLM oferece wrappers que encapsulam essa inteligência, como a capacidade de resumo de texto com Scikit-LLM, classificação ou extração de informações.
<h2>Como o Scikit-LLM Simplifica o Resumo de Texto</h2>
Uma das aplicações mais destacadas do Scikit-LLM é justamente o resumo de texto. Tradicionalmente, o resumo de documentos longos exigia algoritmos de NLP complexos ou abordagens baseadas em regras que eram difíceis de escalar e manter. Com a ascensão dos LLMs, essa tarefa se tornou muito mais viável e de alta qualidade, mas ainda exigia conhecimento aprofundado em como interagir com esses modelos de forma eficaz.
O Scikit-LLM preenche essa lacuna, permitindo que os usuários configurem e executem tarefas de resumo de texto com poucas linhas de código. Ele utiliza o modelo de linguagem subjacente (como GPT-3.5, GPT-4, Llama, etc.) para gerar resumos concisos e coerentes, adaptados ao contexto desejado. Isso transforma o processo de resumir textos usando LLMs de uma tarefa complexa para algo que pode ser incorporado rapidamente em qualquer pipeline de dados existente.
<h3>Vantagens na Prototipagem Rápida e Interoperabilidade</h3>
A grande vantagem do Scikit-LLM para tarefas como resumo de texto é a sua facilidade de uso e o suporte à prototipagem rápida. Desenvolvedores podem experimentar diferentes LLMs e configurações com mínima alteração de código, acelerando o ciclo de desenvolvimento de novas aplicações.
Facilidade de Uso: A interface no estilo Scikit-learn reduz a curva de aprendizado para quem já trabalha com Machine Learning.Prototipagem Rápida: Permite testar diferentes modelos de linguagem e estratégias de prompt com agilidade.Interoperabilidade: Integra-se perfeitamente com outras ferramentas e bibliotecas do ecossistema Python e Scikit-learn, facilitando a construção de pipelines de dados complexos.Redução de Código Boilerplate: Automatiza grande parte da lógica de interação com LLMs, liberando o desenvolvedor para focar na solução do problema.
Essa interoperabilidade é um diferencial competitivo, pois permite combinar as capacidades generativas dos LLMs com técnicas tradicionais de pré-processamento, validação e avaliação do Scikit-learn. [LINK_INTERNO]
<h2>Além do Resumo: Outras Aplicações e o Impacto no Mercado</h2>
Embora o resumo de texto com Scikit-LLM seja uma aplicação poderosa, a biblioteca oferece muito mais. Ela pode ser utilizada em uma vasta gama de tarefas de NLP, como:
Classificação de Texto: Categorizar documentos, e-mails ou comentários.Extração de Informações: Identificar entidades nomeadas, fatos ou dados específicos em um texto.Análise de Sentimento: Avaliar o tom e a emoção de um conteúdo.Geração de Dados Sintéticos (Data Augmentation): Criar novos exemplos para treinar modelos, especialmente útil em cenários com poucos dados.Anotação de Dados (Data Annotation): Acelerar o processo de rotulagem de grandes volumes de texto, servindo como um pré-rotulador.
O impacto dessas capacidades no mercado é significativo. Empresas de tecnologia, startups de IA e equipes de ciência de dados podem agora desenvolver e implantar soluções baseadas em LLMs muito mais rapidamente. Isso acelera a inovação em áreas como atendimento ao cliente (chatbots mais inteligentes), análise de mercado (resumo de relatórios e notícias), gestão de conteúdo (geração automática de meta descrições ou resumos para artigos) e automação de processos (extração de dados de documentos legais).
<h2>O Que Esperar a Seguir para o Scikit-LLM e a IA</h2>
A crescente adoção de ferramentas como o Scikit-LLM aponta para uma tendência clara: a democratização e a facilitação do uso de tecnologias de IA avançadas. À medida que os LLMs se tornam mais poderosos e acessíveis, a necessidade de interfaces que os integrem harmoniosamente aos fluxos de trabalho existentes só aumenta. O Scikit-LLM está na vanguarda dessa evolução, oferecendo uma ponte robusta entre o aprendizado de máquina tradicional e a nova era da IA generativa.
Espera-se que a biblioteca continue a evoluir, adicionando suporte a mais modelos, aprimorando suas capacidades de resumo de texto e expandindo para outras tarefas de IA. Para desenvolvedores, aprender a usar ferramentas como o Scikit-LLM será cada vez mais essencial para construir aplicações de IA eficientes e escaláveis. Você pode explorar a documentação e os exemplos no repositório oficial do projeto para começar a experimentar: Scikit-LLM no GitHub.
<h2>Conclusão</h2>
O Scikit-LLM representa um avanço significativo na forma como interagimos com os Large Language Models. Ao integrar a potência dos LLMs com a familiaridade do Scikit-learn, ele remove barreiras técnicas e acelera o desenvolvimento de aplicações de NLP, especialmente em tarefas como o resumo de texto. Sua abordagem intuitiva, combinada com a capacidade de prototipagem rápida e interoperabilidade, o posiciona como uma ferramenta indispensável para qualquer profissional de IA que busca inovar e otimizar seus projetos.
<h2>FAQ: Perguntas Frequentes sobre Scikit-LLM e Resumo de Texto</h2>
<h3>1. O Scikit-LLM funciona com qualquer Large Language Model?</h3>
O Scikit-LLM foi projetado para ser agnóstico em relação ao modelo, mas atualmente suporta LLMs que possuem APIs acessíveis, como os modelos da OpenAI (GPT-3.5, GPT-4) e outros modelos open-source via frameworks como o Hugging Face. A lista de modelos suportados está em constante expansão, visando oferecer flexibilidade aos usuários para escolher o LLM mais adequado para suas necessidades de resumo de texto ou outras tarefas.
<h3>2. Qual a principal vantagem de usar Scikit-LLM para resumo de texto em comparação com APIs diretas de LLMs?</h3>
A principal vantagem é a familiaridade e a consistência. Ao integrar os LLMs ao ecossistema Scikit-learn, o Scikit-LLM permite que os cientistas de dados utilizem os mesmos padrões e métodos (.fit(), .predict()) que já conhecem. Isso simplifica a prompt engineering, o gerenciamento de chaves de API, a avaliação de modelos e a integração em pipelines de Machine Learning existentes, tornando o processo de resumo de texto com LLMs muito mais eficiente e menos propenso a erros em um ambiente de produção.
Gostou da notícia?
Inscreva-se na nossa newsletter e receba as principais novidades sobre inteligência artificial diretamente no seu e-mail.





