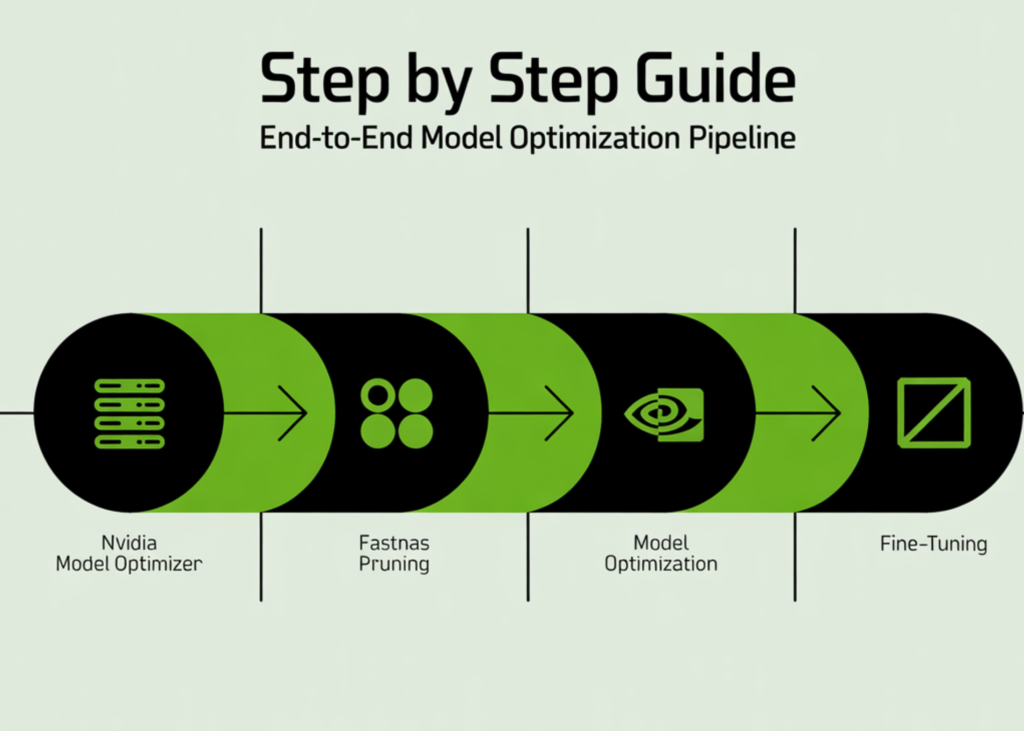
Modelos de deep learning, apesar de seu poder, frequentemente exigem recursos computacionais significativos, tornando sua implantação em ambientes com restrições de hardware um desafio. No entanto, ferramentas avançadas como o NVIDIA Model Optimizer, combinado com técnicas como FastNAS Pruning e fine-tuning, estão revolucionando a forma como abordamos a eficiência desses modelos. Este artigo explora um guia completo para construir uma pipeline de otimização de ponta a ponta, permitindo que desenvolvedores reduzam drasticamente a complexidade de modelos sem sacrificar seu desempenho, tudo isso utilizando o acessível ambiente do Google Colab.
A Necessidade Urgente da Otimização em Deep Learning
Com a crescente adoção da Inteligência Artificial (IA) em dispositivos de borda, como smartphones e equipamentos industriais, a capacidade de executar modelos eficientemente é mais crucial do que nunca. Modelos grandes consomem muita memória, energia e tempo de inferência, o que inviabiliza muitas aplicações práticas. A otimização não é apenas sobre velocidade, mas também sobre sustentabilidade e democratização da IA, permitindo que a tecnologia seja acessível e viável em uma gama maior de cenários.
NVIDIA Model Optimizer e FastNAS Pruning: Entendendo as Ferramentas
Para enfrentar os desafios de eficiência, a NVIDIA oferece um ecossistema robusto de ferramentas. O NVIDIA Model Optimizer é uma suíte que facilita o processo de otimização, desde a fase de treinamento até a implantação. Integrado a ele, técnicas como o FastNAS Pruning se destacam por sua capacidade de podar modelos de forma inteligente.
O Poder do NVIDIA Model Optimizer
O Model Optimizer da NVIDIA é projetado para otimizar modelos de deep learning para desempenho máximo em GPUs NVIDIA. Ele suporta várias técnicas, como quantização e poda (pruning), visando reduzir o consumo de recursos sem comprometer a precisão. Sua integração com frameworks populares como PyTorch e TensorFlow o torna uma ferramenta valiosa para desenvolvedores.
FastNAS Pruning: Reduzindo Complexidade de Forma Inteligente
FastNAS Pruning é uma técnica que combina Neural Architecture Search (NAS) com poda de modelos. Em vez de simplesmente remover pesos de forma aleatória, o FastNAS identifica e remove partes redundantes da rede neural, criando uma sub-rede otimizada. O objetivo é reduzir métricas como FLOPs (Floating Point Operations — operações de ponto flutuante, uma medida de custo computacional) enquanto preserva ou minimiza a perda de desempenho. No exemplo abordado, o alvo era reduzir os FLOPs para cerca de 60 milhões.
Construindo a Pipeline de Otimização na Prática (com Google Colab)
Este guia prático demonstra como criar uma pipeline completa de otimização para um modelo de deep learning, desde o treinamento inicial até a otimização pronta para implantação, utilizando o ambiente do Google Colab. O processo envolve uma série de etapas sistemáticas para garantir que o modelo otimizado mantenha sua performance.
Preparação do Ambiente e Conjunto de Dados
O primeiro passo é configurar o ambiente, instalando as dependências necessárias como nvidia-modelopt e importando as bibliotecas de Python. A reprodutibilidade é garantida com a inicialização de sementes aleatórias. O conjunto de dados CIFAR-10, amplamente utilizado para classificação de imagens, é então preparado, incluindo transformações de dados e a criação de carregadores de dados (data loaders). Parâmetros-chave, como o tamanho do batch e o número de épocas para treinamento, são definidos para controlar o experimento.
Treinamento do Modelo Base (ResNet)
Uma arquitetura ResNet é definida e treinada para estabelecer uma linha de base de desempenho. Este modelo não otimizado serve como ponto de comparação para avaliar a eficácia das técnicas de poda e ajuste fino. O treinamento inicial é crucial para garantir que o modelo aprenda a tarefa adequadamente antes de qualquer modificação estrutural.
Aplicação do Pruning com FastNAS
Com o modelo base treinado, o FastNAS Pruning é aplicado. Esta etapa envolve a sistemática redução da complexidade do modelo sob restrições de FLOPs, mantendo o desempenho. Um aspecto importante é o tratamento de possíveis problemas de compatibilidade no mundo real e a restauração da sub-rede otimizada, que é a versão do modelo com os componentes desnecessários removidos. O processo busca atingir um balanço entre a redução de FLOPs e a preservação da acurácia.
Fine-Tuning para Recuperar a Precisão
Após a poda, mesmo que inteligente, pode haver uma leve queda na precisão do modelo. Para remediar isso, a sub-rede otimizada passa por um processo de fine-tuning (ajuste fino). Durante esta fase, o modelo é retreinado com um número menor de épocas para recuperar qualquer precisão perdida, garantindo que o modelo final seja tanto eficiente quanto preciso. Ao final, temos um fluxo de trabalho completo que leva um modelo do treinamento à otimização pronta para implantação, tudo dentro de uma única configuração simplificada.
Para uma implementação detalhada e interativa, confira o Caderno de Codificação de Implementação Completa.
Impactos e Cenários de Aplicação da Otimização
A capacidade de otimizar modelos de deep learning tem implicações profundas para diversos setores:
Empresas e Mercado
Empresas podem reduzir significativamente os custos de infraestrutura de inferência, além de viabilizar novos produtos e serviços que antes eram inviáveis devido às limitações de hardware. Isso abre portas para IA em dispositivos IoT (Internet of Things), veículos autônomos e outros sistemas embarcados.
Desenvolvedores e Inovação
Desenvolvedores ganham acesso a ferramentas mais eficientes e acessíveis para criar e implantar soluções de IA. A curva de aprendizado para otimização é suavizada, permitindo que mais profissionais explorem o potencial da IA em projetos com recursos limitados.
Sociedade e Sustentabilidade
Modelos mais eficientes consomem menos energia, contribuindo para operações de IA mais sustentáveis e ambientalmente amigáveis. Além disso, a democratização da IA em dispositivos menores pode levar a aplicações mais difundidas e benéficas para a sociedade.
Conclusão
A otimização de modelos de deep learning é um pilar fundamental para o avanço e a aplicação prática da Inteligência Artificial. Através de ferramentas como o NVIDIA Model Optimizer e técnicas avançadas como FastNAS Pruning, é possível construir pipelines eficientes que transformam modelos complexos em soluções ágeis e prontas para implantação. Este guia demonstrou um caminho claro para alcançar essa eficiência, destacando a importância de cada etapa, do treinamento inicial ao fine-tuning, garantindo que o desempenho seja mantido mesmo com uma redução substancial da complexidade. À medida que a demanda por IA cresce, a capacidade de otimizá-los se tornará cada vez mais um diferencial competitivo.
Gostou da notícia? Inscreva-se na nossa newsletter para receber as principais novidades sobre inteligência artificial diretamente no seu e-mail.
Fonte: https://www.marktechpost.com






