Você já se deparou com tutoriais de Deep Learning e sentiu que algumas derivadas simplesmente ‘apareciam’ do nada? Se sim, este artigo é para você! Mergulharemos fundo em uma das mais fundamentais e instrutivas operações no Machine Learning: o cálculo do gradiente da função de perda L1, também conhecida como perda de valor absoluto ou MAE (Mean Absolute Error), em relação a um único peso. Compreender este conceito não só desmistifica a otimização de modelos, mas também aprimora sua capacidade de construir sistemas de IA mais robustos e eficazes.
O Coração da Otimização: Entendendo a Perda L1
No universo do Machine Learning, funções de perda são cruciais. Elas quantificam quão bem (ou mal) um modelo está se saindo ao fazer previsões. A perda L1, ou valor absoluto da diferença entre o valor real e a previsão (|y – y_pred|), é particularmente interessante. Diferente da popular perda L2 (erro quadrático), a L1 penaliza os erros de forma linear, o que a torna especialmente robusta a outliers (valores atípicos), ou seja, pontos de dados que destoam muito do restante.
Modelos de Regressão e a Derivação do Gradiente
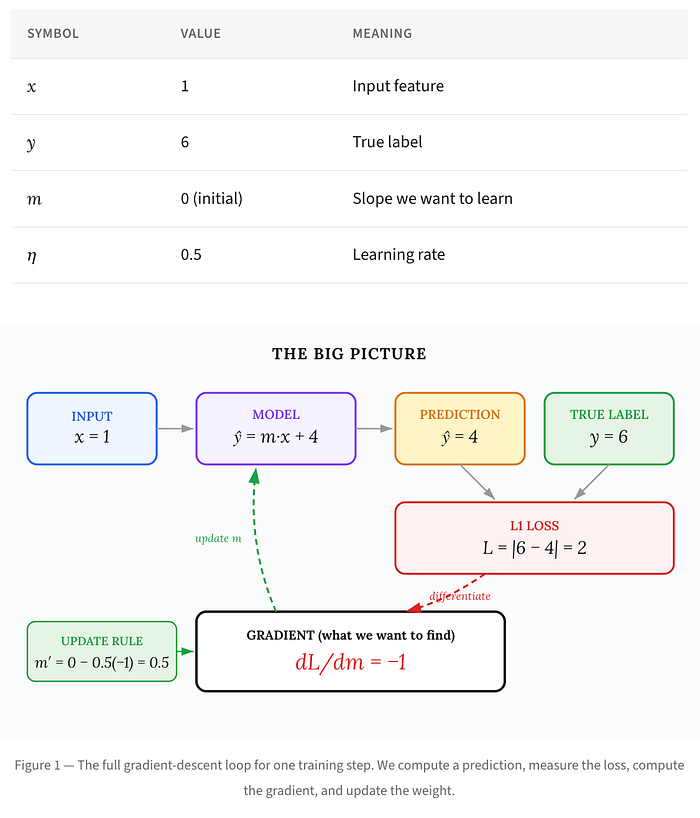
Para ilustrar o gradiente da perda L1, o artigo original utiliza um modelo de regressão simples. Imagine que temos uma equação linear y_pred = w * x + b, onde w é o peso e b é o viés. Nosso objetivo é ajustar w e b para que y_pred se aproxime ao máximo de y. O gradiente descendente é o algoritmo que nos ajuda a fazer isso, movendo-se na direção oposta ao gradiente da função de perda para encontrar o mínimo. Se você quiser saber mais sobre como o Gradiente Descendente funciona, confira nosso guia detalhado.
Cálculo Detalhado com a Regra da Cadeia
A beleza do cálculo do gradiente da perda L1 reside na sua simplicidade e na aplicação direta da Regra da Cadeia. Para uma função de perda L = |y – (w * x + b)| em relação a um peso w, a derivada é dada por dL/dw = sign(y – (w * x + b)) * (-x). A função sign() retorna -1 se o erro é negativo, +1 se positivo, e é indefinida em zero (geralmente tratada como 0 ou -1/1). Esta característica significa que o gradiente L1 aplica uma correção de magnitude constante, independentemente do tamanho do erro, ao contrário da L2 que ajusta a correção proporcionalmente ao erro. O artigo original, publicado em Towards AI, explora um exemplo concreto com valores específicos para ilustrar esta derivação, tornando-a acessível mesmo para quem tem pouca experiência com cálculos de derivadas.
L1 vs. L2: Quando Escolher Cada Uma?
A escolha entre a perda L1 e L2 (erro quadrático médio) é um ponto crucial no design de modelos de Machine Learning. Enquanto a L1 é insensível a outliers, oferecendo robustez (pois o ajuste é linear e constante), a L2 é altamente sensível a eles, penalizando erros maiores de forma mais acentuada devido ao seu termo quadrático. Essa diferença fundamental influencia diretamente a ‘personalidade’ do seu modelo. A perda L1 é frequentemente utilizada em cenários onde a presença de dados atípicos é esperada e se deseja que o modelo seja mais resistente a eles, como em tarefas de compressão de sinal ou análise financeira. A L2, por outro lado, é preferida quando se busca uma solução mais ‘suave’ e onde erros grandes precisam ser fortemente penalizados, sendo a base da regressão de mínimos quadrados.
Impacto e Aplicações no Desenvolvimento de IA
A compreensão profunda do gradiente L1 não é apenas teórica; ela tem um impacto prático significativo no desenvolvimento de IA. A capacidade da L1 de atuar como uma penalidade de regularização (como na regressão LASSO) incentiva a esparsidade do modelo, levando à seleção de características mais importantes e à simplificação do modelo. Isso resulta em modelos mais interpretáveis e eficientes, especialmente em ambientes com alta dimensionalidade de dados. Desenvolvedores e cientistas de dados precisam pesar os prós e contras de cada função de perda para otimizar seus algoritmos e garantir que as soluções de IA sejam não apenas precisas, mas também robustas e generalizáveis.
Gostou da notícia? Inscreva-se na nossa newsletter para receber as principais novidades sobre inteligência artificial diretamente no seu e-mail.
Fonte: https://towardsai.net






