Você já se frustrou ao buscar algo online e não encontrar o que queria, mesmo sabendo que a informação estava lá? A busca tradicional por palavras-chave é poderosa, mas tem um calcanhar de Aquiles: ela falha quando a sua pergunta não corresponde literalmente aos termos exatos do documento. Felizmente, uma nova era está amanhecendo com a Busca Contextual com LLM (Large Language Model), uma abordagem que promete transformar radicalmente a forma como interagimos com grandes volumes de dados, indo muito além das correspondências de texto.
Neste artigo, vamos mergulhar no universo da Busca Contextual com LLM, entender como ela funciona, por que é tão revolucionária e como a combinação de embeddings e metadados está pavimentando o caminho para sistemas de busca incrivelmente inteligentes, capazes de compreender o real significado por trás das suas consultas, e não apenas as palavras.
O Desafio da Busca Tradicional: Por Que Palavras-Chave Não Bastam
Imagine que você está procurando por “soluções para reduzir a pegada de carbono em indústrias”. Um sistema de busca tradicional pode até retornar documentos que contêm essas exatas palavras. Mas e se um artigo crucial usasse termos como “otimização energética em processos fabris” ou “iniciativas de sustentabilidade corporativa”? O sistema de busca por palavras-chave falharia miseravelmente em conectar sua intenção com o conteúdo relevante, pois não há uma correspondência literal.
Essa limitação decorre de sua natureza: a busca tradicional opera com base em índices de palavras, comparando strings de texto. Ela não “entende” o contexto, sinônimos, ou a intenção por trás de uma consulta. É aqui que a Inteligência Artificial, e especificamente os Large Language Models, entram em cena para mudar o jogo, tornando a busca mais humana e inteligente.
Como a <strong>Busca Contextual com LLM</strong> Eleva a Experiência
A Busca Contextual com LLM revoluciona a recuperação de informações ao focar no significado, e não apenas nas palavras. Ela se baseia em duas tecnologias complementares que, quando combinadas, criam um sistema de busca poderosa e flexível.
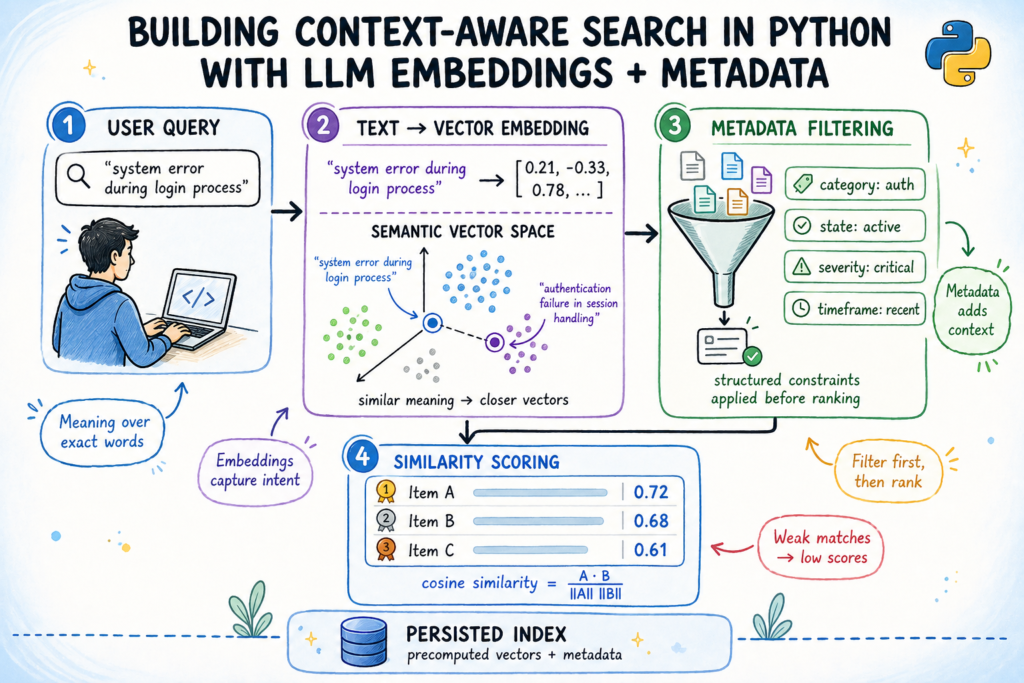
Embeddings: A Linguagem da Semântica para <strong>Busca Contextual</strong>
No coração da busca contextual estão os Embeddings. Pense neles como representações numéricas de palavras, frases ou documentos inteiros, em um espaço multidimensional. Nesses espaços, itens com significados semelhantes são posicionados mais próximos uns dos outros. Ou seja, “cachorro” e “cão” estariam muito próximos, assim como “rei” e “rainha” (e a relação entre eles poderia ser similar à relação entre “homem” e “mulher”).
Os LLMs são treinados para gerar esses embeddings, capturando a semântica de forma robusta. Quando você faz uma consulta, ela é convertida em um embedding. Em seguida, o sistema busca os documentos cujos embeddings são mais “próximos” (semanticamente) ao da sua consulta, independentemente das palavras exatas utilizadas. Isso permite encontrar resultados relevantes mesmo que não haja uma correspondência literal de termos.
Metadata: Enriquecendo o Contexto na Busca
Enquanto os embeddings capturam a semântica do conteúdo textual, os metadados adicionam uma camada crucial de contexto estruturado. Metadados são informações adicionais sobre um documento, como data de criação, autor, tipo de documento, departamento, tags ou categorias específicas.
A combinação de embeddings com metadados permite filtros e refinamentos poderosos. Por exemplo, você pode buscar por “soluções de sustentabilidade” (usando embeddings) e, ao mesmo tempo, filtrar os resultados para mostrar apenas documentos “publicados após 2022” ou “escritos pelo departamento de engenharia” (usando metadados). Essa sinergia cria um sistema de busca incrivelmente preciso e adaptável.
Implementando a <strong>Busca Contextual com LLM</strong> em Python
Para desenvolvedores e empresas interessadas em construir suas próprias soluções de Busca Contextual com LLM, Python se destaca como a linguagem de escolha, devido ao seu vasto ecossistema de bibliotecas e frameworks para IA e Machine Learning. A arquitetura básica geralmente envolve as seguintes etapas:
Arquitetura e Ferramentas para <strong>Busca Contextual em Python</strong>
Essa arquitetura permite que as aplicações não apenas encontrem informações relevantes, mas também as utilizem como contexto para um LLM gerar respostas coesas e informativas, um pilar fundamental dos sistemas de perguntas e respostas avançados (Q&A systems) e agentes de IA.
Impactos e Oportunidades da <strong>Busca Contextual com LLM</strong>
A implementação de sistemas de busca contextual tem implicações profundas em diversos setores:
Essa tecnologia democratiza o acesso ao conhecimento, permitindo que qualquer pessoa com uma pergunta obtenha uma resposta contextualizada, mesmo que não saiba a terminologia exata.
Desafios e Considerações para a Adoção
Apesar do vasto potencial, a implementação de sistemas de Busca Contextual com LLM não está isenta de desafios. O custo computacional para gerar e armazenar embeddings em larga escala pode ser significativo, e a complexidade de gerenciar a infraestrutura de LLMs e bancos de dados vetoriais exige expertise técnica. Além disso, questões como a privacidade dos dados, a governança dos modelos e o possível viés inerente aos dados de treinamento dos LLMs precisam ser cuidadosamente endereçadas para garantir um uso ético e responsável.
O Futuro da Busca com IA e LLMs
A evolução da Busca Contextual com LLM é contínua. À medida que os modelos de linguagem se tornam mais sofisticados e eficientes, podemos esperar sistemas de busca ainda mais inteligentes, capazes de entender nuances, raciocinar sobre as informações e até mesmo antecipar as necessidades dos usuários. A integração com sistemas multimodais, que combinam texto, imagem e vídeo, também representa uma fronteira promissora, tornando a busca ainda mais rica e intuitiva. Veremos um movimento crescente em direção a agentes de IA autônomos que utilizam a busca contextual para operar de forma mais eficaz.
Conclusão
A era da busca por palavras-chave está gradualmente sendo substituída por sistemas que realmente compreendem o que buscamos. A Busca Contextual com LLM, impulsionada por embeddings e metadados, representa um salto gigantesco nessa evolução, oferecendo uma ponte entre a complexidade da linguagem humana e a eficiência da recuperação de informações digitais. Para desenvolvedores, empresas e usuários, essa tecnologia não é apenas um avanço técnico, mas uma promessa de acesso ao conhecimento mais intuitivo, relevante e transformador. É hora de ir além das palavras e abraçar o significado.
FAQ: Perguntas Frequentes sobre <strong>Busca Contextual com LLM</strong>
1. Qual a diferença entre busca por palavras-chave e busca contextual com LLM?
A busca por palavras-chave (ou busca exata) compara termos literais em sua consulta com os termos em documentos. Se as palavras não corresponderem exatamente, os resultados podem ser perdidos. A Busca Contextual com LLM, por outro lado, utiliza embeddings para entender o significado ou a semântica de sua consulta e dos documentos. Ela encontra informações relevantes mesmo que não usem as mesmas palavras, mas expressem a mesma ideia.
2. Por que metadados são importantes na busca contextual?
Metadados (como autor, data, tipo de documento) adicionam informações estruturadas que os embeddings textuais sozinhos não capturam. Eles permitem refinar a busca com filtros específicos, tornando-a mais precisa e relevante. Por exemplo, você pode buscar por um tópico (semântica) e filtrar apenas por documentos de um certo ano ou departamento (metadados), combinando o melhor dos dois mundos para uma Busca Contextual com LLM ainda mais eficaz.
Gostou da notícia?
Inscreva-se na nossa newsletter e receba as principais novidades sobre inteligência artificial diretamente no seu e-mail.





