Se você já interagiu com Large Language Models (LLMs) ou planeja construir aplicações em escala, provavelmente já percebeu: chamar uma API de um LLM de forma massiva é caro e, muitas vezes, lento. Essa é uma barreira significativa para a adoção generalizada e o custo-benefício dessas tecnologias. Mas existe uma solução poderosa que está mudando esse cenário: o Cache de Inferência em LLMs. Entender como essa técnica funciona e por que ela é crucial é o primeiro passo para desbloquear todo o potencial da inteligência artificial generativa em suas operações.
O Que é o Cache de Inferência e Por Que Ele Importa?
O conceito de cache não é novo na computação, mas sua aplicação no contexto dos LLMs ganha uma importância estratégica. Basicamente, o cache de inferência permite que o modelo “lembre” e reutilize cálculos que já foram feitos para partes de uma entrada (prompt) ou para sequências de texto geradas anteriormente. Imagine que você está conversando com um assistente de IA: a cada nova pergunta, o modelo precisa processar todo o histórico da conversa para manter o contexto. Sem um cache, ele recalculava as mesmas informações repetidamente.
A principal razão pela qual o Cache de Inferência em LLMs é vital é dupla: custo e velocidade.
Redução de Custos: Cada computação de token consome recursos computacionais (GPUs) e, consequentemente, dinheiro. Ao evitar o reprocessamento, o cache diminui drasticamente a quantidade de cálculo necessária, resultando em economia substancial em escala.Aumento de Velocidade (Latência): Em vez de esperar que o modelo recalcule trechos inteiros de um prompt ou contexto, o cache entrega esses resultados instantaneamente. Isso acelera o tempo de resposta, tornando as aplicações de IA mais rápidas e fluidas para o usuário final.
Como o Cache de Inferência em LLMs Funciona na Prática?
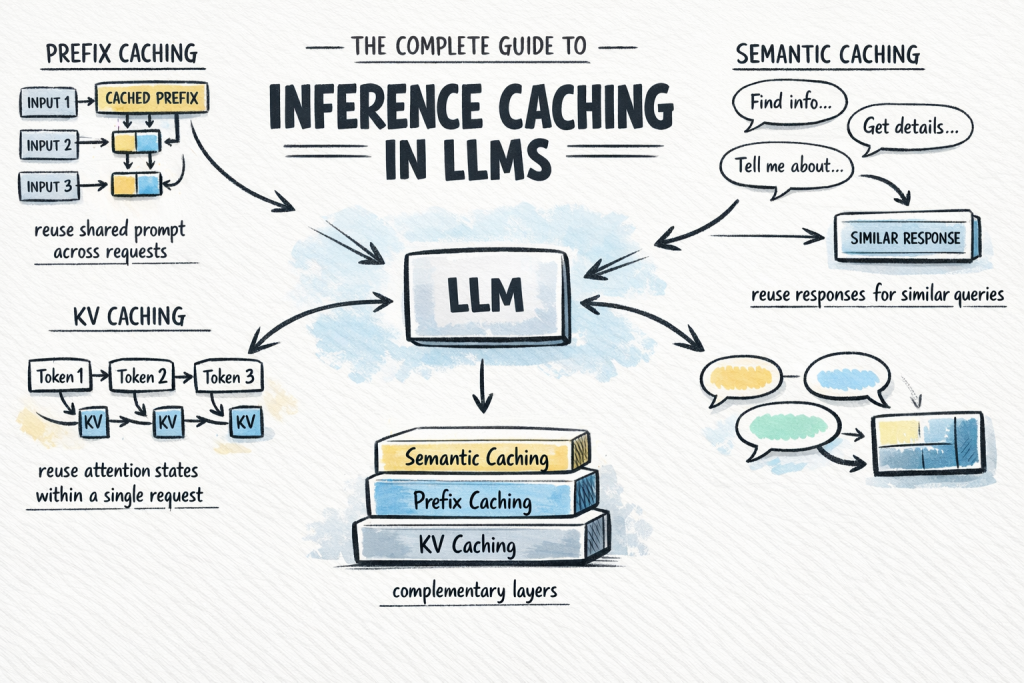
Para entender o Cache de Inferência em LLMs, precisamos olhar para como os modelos processam as entradas e geram as saídas. Os LLMs utilizam uma arquitetura baseada em Transformers, que depende de um mecanismo de atenção para ponderar a importância de diferentes partes do input. Durante esse processo, são geradas representações intermediárias, chamadas de chaves (keys) e valores (values) — o famoso KV Cache.
O Papel do KV Cache
O KV Cache é o coração do cache de inferência. Quando um LLM processa uma sequência de tokens (seja o prompt inicial ou os tokens já gerados), ele calcula as “chaves” e “valores” para cada token. Essas chaves e valores são essenciais para o mecanismo de atenção que decide quais partes da entrada são mais relevantes para prever o próximo token. Em vez de descartar essas chaves e valores após cada etapa de geração de token, o cache os armazena.
Processamento do Prompt (Pre-fill Phase): Quando você envia um prompt longo para um LLM, o modelo calcula as chaves e valores para todos os tokens do prompt. Com o cache, se um prompt subsequente começa com a mesma sequência de tokens, o modelo pode simplesmente reutilizar as chaves e valores já calculados para essa parte comum, focando a computação apenas nos tokens novos.Geração de Resposta (Decoding Phase): Após processar o prompt, o LLM gera um token por vez. Cada token gerado é adicionado à sequência de entrada para prever o próximo. Novamente, as chaves e valores para os tokens já gerados são cacheados, evitando que o modelo recalcule a atenção sobre o mesmo histórico a cada novo token.
Isso é particularmente útil em cenários como chatbots, onde o histórico da conversa é um prefixo constante para as novas interações, ou em aplicações que recebem prompts muito semelhantes de diferentes usuários ou em diferentes momentos.
Impacto e Vantagens Competitivas do Cache de Inferência
A implementação eficaz do Cache de Inferência em LLMs traz um leque de benefícios que se estendem por toda a cadeia de valor da IA:
Para Desenvolvedores: A capacidade de reduzir a latência e o custo permite a criação de aplicações mais responsivas e financeiramente viáveis. Isso abre portas para designs de interação mais complexos e ambiciosos, onde a velocidade é crucial. Desenvolvedores podem experimentar mais, iterar mais rápido e entregar experiências superiores.Para Empresas e Startups: Reduzir os custos operacionais de LLMs significa que empresas podem escalar suas ofertas de IA sem que o custo de inferência se torne proibitivo. Isso se traduz em maior lucratividade, a capacidade de competir com preços mais agressivos e a flexibilidade para investir em inovação. Em um mercado acirrado, a eficiência de inferência pode ser um diferencial competitivo gigante.Para Usuários Finais: A melhoria mais perceptível é a experiência do usuário. Aplicações que respondem instantaneamente parecem mais inteligentes, eficientes e agradáveis de usar. Isso aumenta a satisfação e a retenção, incentivando o uso contínuo da tecnologia de IA.
Além disso, o cache de inferência facilita o uso de LLMs em dispositivos com recursos limitados, ao reduzir a carga computacional por requisição, embora seu impacto seja mais notável em ambientes de servidor para escalar operações. Em ambientes de nuvem, a otimização pode significar o uso de menos GPUs ou por menos tempo, impactando diretamente os custos de infraestrutura.
Desafios e Considerações ao Implementar o Cache de Inferência
Embora o Cache de Inferência em LLMs ofereça vantagens significativas, sua implementação não está isenta de desafios:
Gerenciamento de Memória: O KV Cache pode consumir uma quantidade considerável de memória da GPU, especialmente para prompts longos ou um grande número de requisições simultâneas. Gerenciar essa memória de forma eficiente é crucial para evitar gargalos e garantir que o cache não se torne um fardo.Invalidação de Cache: Quando o contexto ou os parâmetros do modelo mudam, o cache precisa ser invalidado para garantir que os resultados sejam sempre precisos e atualizados. Estratégias robustas de invalidação são essenciais.Coerência em Sistemas Distribuídos: Em sistemas onde vários servidores ou GPUs estão atendendo a requisições, garantir que todos os caches estejam sincronizados e oferecendo os mesmos resultados consistentes pode ser complexo.Complexidade da Implementação: Integrar o cache de inferência de forma otimizada nos serving frameworks de LLMs (como vLLM, TGI ou mesmo implementações personalizadas) exige conhecimento aprofundado da arquitetura do modelo e do hardware.
Muitas ferramentas e bibliotecas modernas para servir LLMs já incorporam e otimizam o uso do KV Cache, tornando a tarefa mais acessível para desenvolvedores, mas a personalização e a maximização da eficiência ainda exigem consideração cuidadosa.
O Que Esperar do Futuro do Cache de Inferência em LLMs?
O campo da otimização de LLMs está em constante evolução. Espera-se que o Cache de Inferência em LLMs continue sendo aprimorado com técnicas ainda mais sofisticadas:
Caches Adaptativos: Sistemas de cache que ajustam dinamicamente sua estratégia com base no padrão de uso e nos recursos disponíveis.Caches Multi-nível: Utilização de diferentes camadas de cache (CPU, RAM, disco) para diferentes tipos de dados ou com diferentes latências, otimizando o custo-benefício.Integração Mais Profunda: Frameworks e plataformas de LLMs se tornarão ainda mais eficientes na gestão automática do cache, abstraindo a complexidade para o desenvolvedor.Novas Arquiteturas: Pesquisas em arquiteturas de modelos que são intrinsecamente mais eficientes com cache ou que permitem formas inovadoras de cache para contextos muito longos.
Com o avanço da pesquisa e o aumento da demanda por IA em escala, o cache de inferência não será apenas uma técnica de otimização, mas um componente fundamental da infraestrutura de qualquer aplicação de LLM.
FAQ: Perguntas Frequentes sobre Cache de Inferência em LLMs
O que é o Cache de Inferência em LLMs?
É uma técnica que armazena e reutiliza cálculos intermediários (chaves e valores do mecanismo de atenção) feitos por um Large Language Model para partes de prompts ou sequências de texto já geradas. Isso evita que o modelo recalcule as mesmas informações repetidamente.
Quais são os principais benefícios de usar o Cache de Inferência?
Os dois principais benefícios são a redução significativa de custos operacionais, pois menos computação é necessária, e a melhoria drástica da velocidade de inferência (menor latência), tornando as aplicações de IA mais rápidas e responsivas para os usuários.
Gostou da notícia?
Inscreva-se na nossa newsletter e receba as principais novidades sobre inteligência artificial diretamente no seu e-mail.





